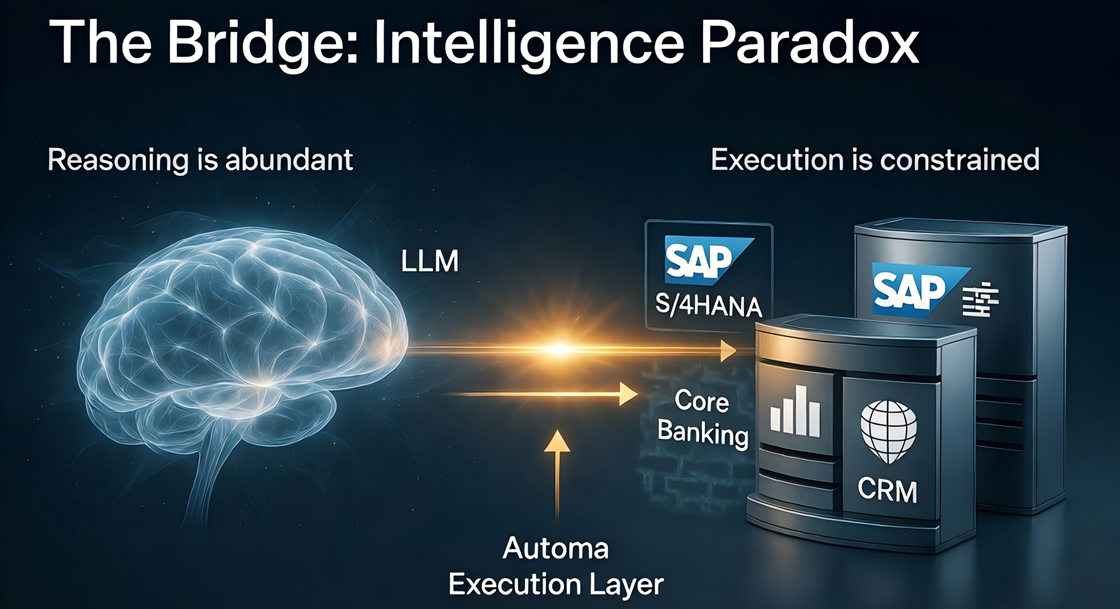
Why Execution Is the Only Metric That Matters in 2026
At GTC 2026, Jensen Huang formalized the operating model of the AI economy: Perception → Generation → Reasoning → Execution.
AI has already solved intelligence, what remains unsolved is execution, the next decade will not be defined by how fast we generate intelligence, but by how precisely we execute it. That’s where Automa draws the line.
 From Token Production to Utility per Token
From Token Production to Utility per Token
GTC 2026 made one thing crystal clear: the token is now the fundamental unit of AI production. Yet production alone creates no enterprise value. Idle tokens are simply idle compute.
The metric that actually matters is Utility per Token: How effectively those tokens become compliant, auditable, revenue-generating actions.
NVIDIA lowered the floor of AI costs. Automa raises the ceiling of outcomes by turning raw intelligence into real business results.
The Structural Gap: Intelligence vs. Execution
Foundation models have made intelligence abundant. Yet enterprise systems remain fundamentally misaligned:
LLMs can reason, but cannot act.
RPA can act, but cannot reason.
Integration platforms connect systems, but lack autonomy.
The bottleneck is no longer intelligence, it’s execution.
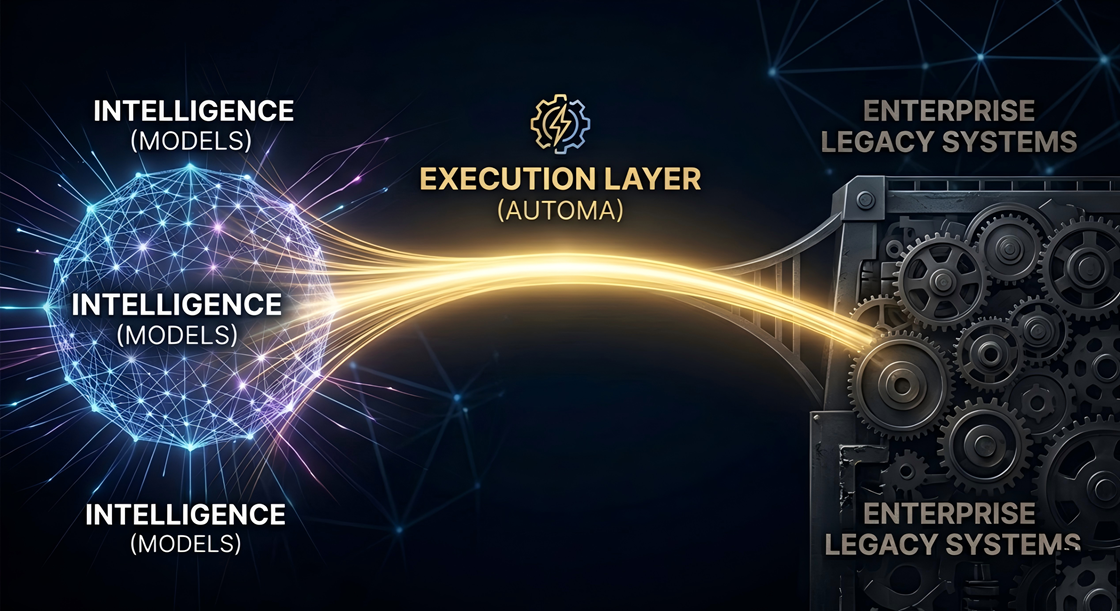
Automa defines the Execution Layer: The orchestration grid that securely translates AI reasoning into deterministic, auditable action inside your existing systems. At its core, Automa provides a local-first orchestration runtime that translates model outputs into API calls, UI actions, and system-level transactions across ERP, CRM, and legacy environments, without requiring system replacement.
Bridging the Data Layer to the Execution Layer
Technologies like cuDF and cuVS have commoditized lightning-fast structured and vector data processing. But faster insights are worthless if they never trigger real-world action.
Automa closes this gap with its Intelligent Process Automation (IPA) framework:
AI Agents produce context-aware decisions.
Automa orchestrates the workflow.
RPA bots execute fully audited actions inside SAP S/4HANA, CRM platforms, and core banking systems.
Everything stays compliant, auditable, and within your firewall, zero external data movement.
 Real-World Impact: From AI Insight to Business Execution
Real-World Impact: From AI Insight to Business Execution
A global financial institution used Automa to convert AI-driven loan approval reasoning directly into system execution, via natural-language task plans translated into SAP-compliant workflows.
Results were immediate:
Validated transactions and compliant core-banking updates
Full audit trails preserved end-to-end
80% reduction in processing time
Up to 6× faster ROI realization
Automa has already helped enterprises worldwide automate over 100 million workflows with the same precision.
From SaaS to Agent-Oriented Systems
Traditional SaaS was built for human operation, static interfaces and manual dependency. The new standard is Agent-as-a-Service: autonomous, context-aware, and continuously optimizing.
In this paradigm, NVIDIA supplies the computational power. Automa acts as the execution and orchestration layer that converts that power into tangible outcomes.
Private Agent Factories and Data Sovereignty
For banking, insurance, and public-sector organizations, the real constraint isn’t capability — it’s control. Legacy systems, GDPR, FINRA, SOC 2, and strict data-residency rules demand more than “security.” They demand data sovereignty.
Automa’s Local-First architecture lets enterprises build Private Agent Factories:
On-premise or hybrid deployment
All execution stays inside firewall boundaries
Every action is auditable and compliant by design
The data center stops being a cost center. It becomes a Sovereign Token Factory — where every token consumed produces controlled, value-creating execution.
Pilot-as-a-Service: Strategic Agility Without Technical Debt
GPU architectures evolve yearly (Blackwell → Rubin), models improve exponentially, and compute demand grows without bound. Long-term commitments now carry real obsolescence risk.
Automa’s Pilot-as-a-Service changes the game:
Deploy in controlled environments within 2 to 4 weeks
Validate real execution outcomes with zero heavy infrastructure investment
No long-term lock-in
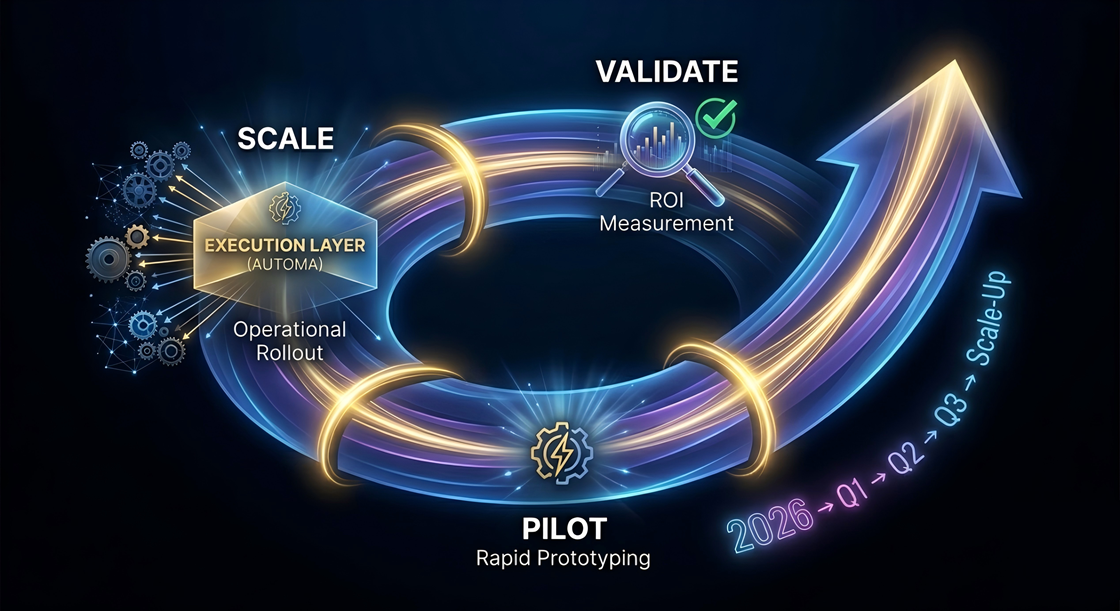 Enterprises using Pilot-as-a-Service typically demonstrate measurable ROI within 6–8 weeks and scale only when value is proven. It’s the smartest way to stay aligned with the fastest-moving layer of the AI stack.
Enterprises using Pilot-as-a-Service typically demonstrate measurable ROI within 6–8 weeks and scale only when value is proven. It’s the smartest way to stay aligned with the fastest-moving layer of the AI stack.
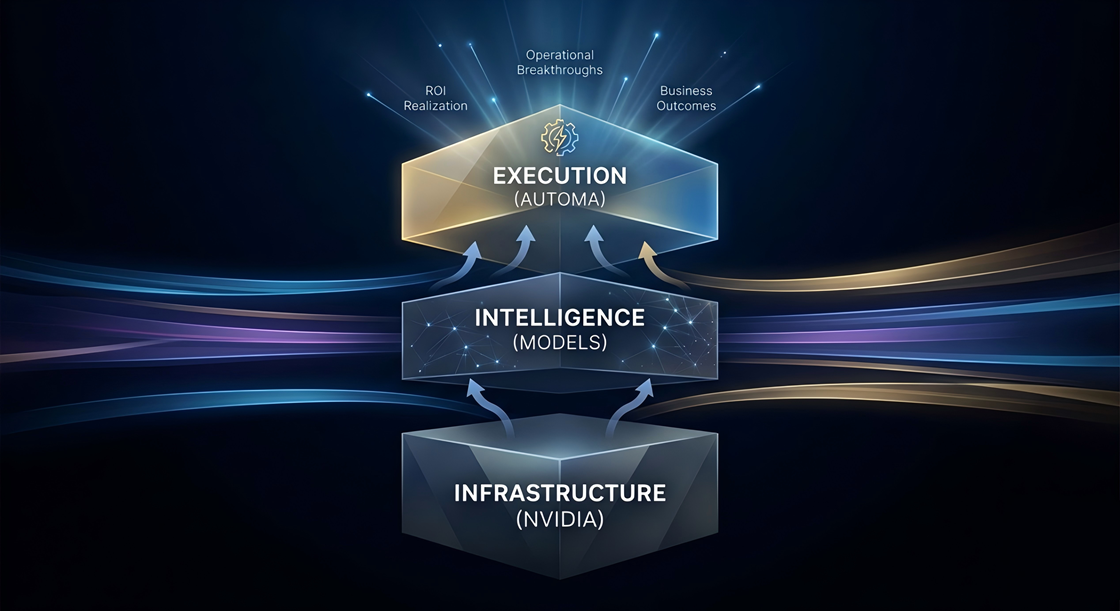
The New Enterprise AI Stack
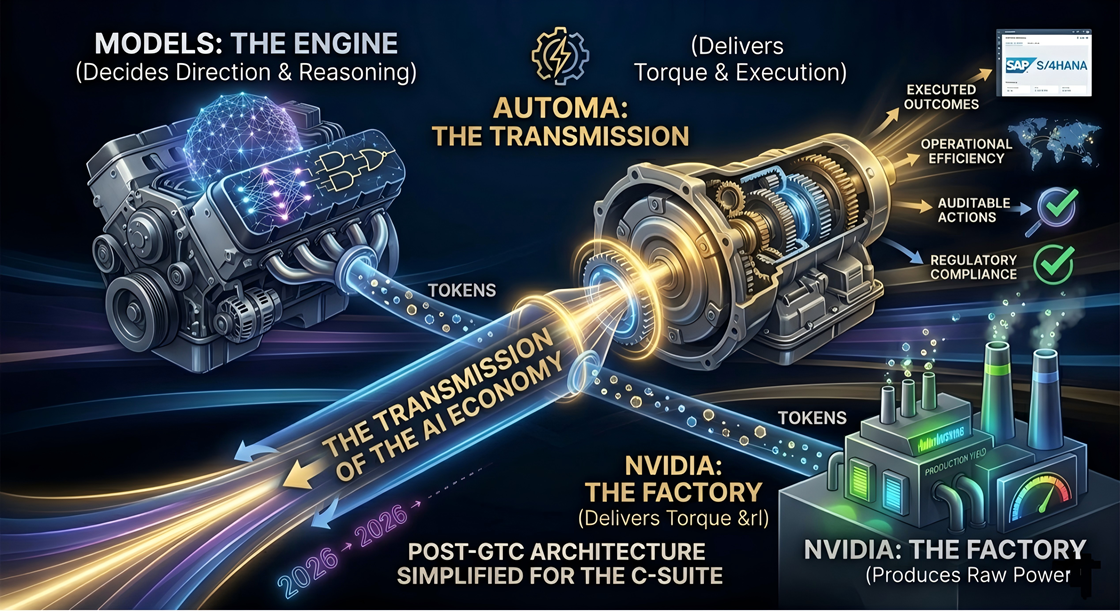
Post-GTC, the architecture is clear:
Infrastructure (NVIDIA) → Token generation
Models → Reasoning & planning
Automa → Execution & orchestration (deterministic, auditable actions)
Or, more intuitively: NVIDIA: The Factory (produces power) Models: The Engine (sets direction) Automa: The Transmission (delivers execution)
Conclusion: Execution Defines the AI Economy
Model performance, parameter scale, and compute capacity remain important upstream metrics. But only execution creates downstream enterprise value — business outcomes, operational efficiency, and revenue.
The companies that will lead the next decade are not the ones generating the most intelligence or owning the most infrastructure. They are the ones that can operationalize intelligence, securely, compliantly, and at scale.
Automa is purpose-built for exactly that layer.
If your organization is moving beyond AI experimentation, three questions matter most:
How are tokens translated into completed work?
How is execution governed across enterprise systems?
How is data sovereignty maintained?
If these remain unanswered, your AI stack is still incomplete.
Automa completes it.
Explore Automa Enterprise’s Pilot-as-a-Service and see how your AI can move from reasoning to execution in as little as 2 to 4 weeks. https://www.goautoma.com/enterprise
