GPT-5.4 Lets AI Take Over Operating Systems
OpenAI released the newest artificial intelligence model, GPT-5.4. This system combines logical reasoning and code writing functions. It takes over computer operating systems directly. In multiple objective tests, it scored higher than Gemini 3.1 Pro and Claude Opus 4.6.
Tech companies changed the direction of AI development. Previous AI acted like a consultant. Users asked questions, and it provided text advice. Now, GPT-5.4 acts like an employee. It looks at the screen, uses the mouse, and presses keys. It completes specific work instead of humans.
In basic ability tests, GPT-5.4 achieved these specific results:
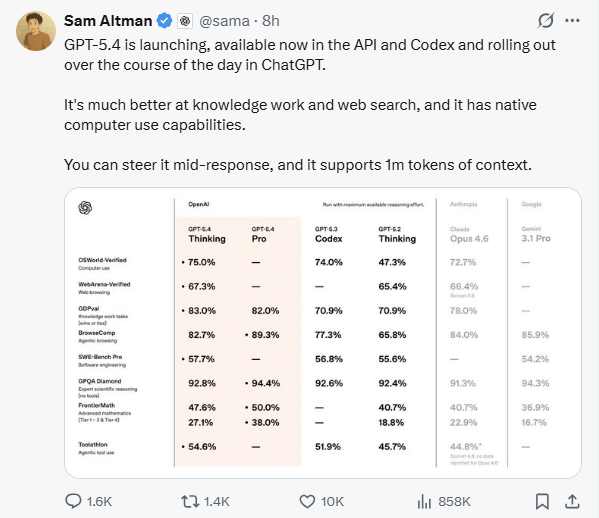
ARC-AGI-2 Abstract Reasoning:GPT-5.4 scored 83.3%. Gemini 3.1 Pro scored 77.1%, and Claude Opus 4.6 scored 68.8%.
Coding and Math:The system ranked first in both the SWE-Bench Pro coding test and the FrontierMath math test.
How GPT-5.4 Reads Screens and Uses Tools?
GPT-5.4 changes how the system schedules computing resources and operates software specifically.
Visual Perception and Native Computer Control
The system does not use special Application Programming Interfaces (APIs) to connect to other software. It captures computer screen images directly. The system identifies buttons, text boxes, and menus on the screen. Then, it writes code to control mouse movement and keyboard input. Developers usually use the Playwright library to execute these actions. The system switches freely between browsers and different office software.
The model provides "Original" and "High" image input levels. The system supports up to 10.24 million total pixels of input. This allows the system to clearly see tiny text on webpages. In the MMMU-Pro visual perception test, GPT-5.4 achieved an 81.2% success rate. The previous generation model achieved 79.5%.
Tool Search Mechanism
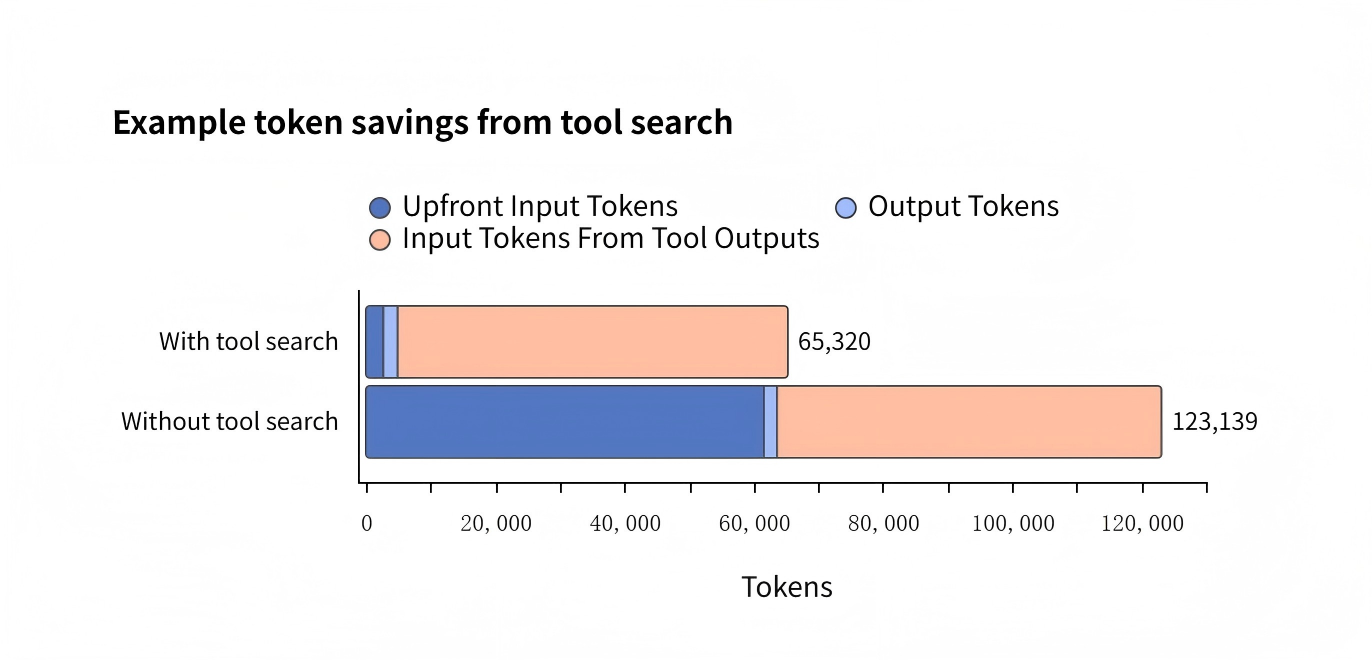
Previous systems needed to read the instruction manuals for all tools at once when handling complex tasks. This increased operating costs.
GPT-5.4 adds a "Tool Search" function. The system keeps only a short list of tool names internally. When it faces a specific problem, it searches the list automatically and loads only that specific tool. This works like a repair worker fixing a pipe. He takes only one wrench from a drawer, instead of carrying the whole heavy toolbox. In the Scale agency benchmark test, this mechanism reduced Token use by 47%.
Dynamic Adjustment in Thinking Mode
When handling tasks that require long thinking times, the GPT-5.4 Thinking mode allows users to enter new instructions midway.
After receiving new instructions, the system changes its next operation direction immediately. It does not need to abandon previous work and start over. This works like giving a driver a new destination. The driver turns directly at the next intersection, instead of driving back to the start. This reduces the time users spend modifying prompts repeatedly.
83% Win Rate: Test Data Verifies GPT-5.4's Real Office Performance
GPT-5.4 produced specific test data in real office and development scenarios.
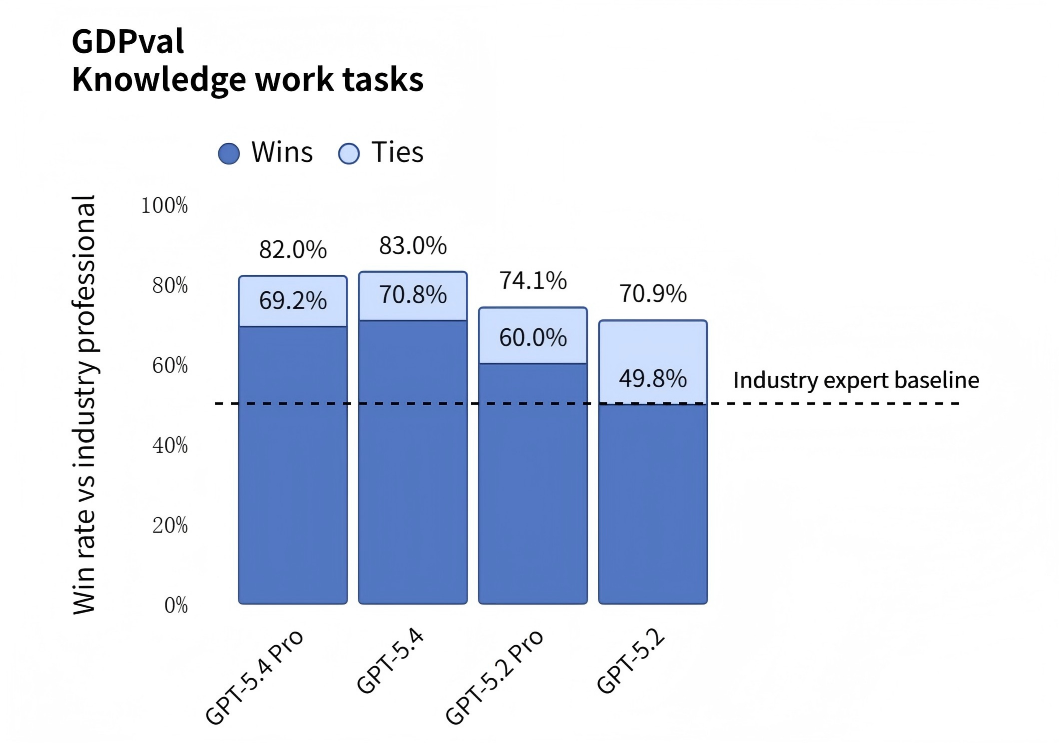
Business Office Execution: In the GDPval business benchmark test, GPT-5.4 achieved an 83.0% win rate. This test requires the AI to produce 44 specific work results across 9 US industries.
Spreadsheet Processing: In an Excel financial modeling test simulating a junior investment bank analyst, GPT-5.4 scored an average of 87.3%.
Presentation Creation: The system formats and creates PowerPoints directly. Human evaluators preferred slides made by GPT-5.4 in 68.0% of cases.
Operating System and Web Testing
OSWorld Test: This test requires AI to operate computers like humans. GPT-5.4 achieved a 75.0% success rate. The human average score was 72.4%. The system's skill in operating computers exceeds the human average.
Web Operation: Relying only on screen captures to observe webpages, GPT-5.4 reached an operation success rate of 92.8%.
Automated Game Development: In the SWE-Bench Pro coding test, the model's accuracy reached 57.7%. Developers used it to complete game projects:
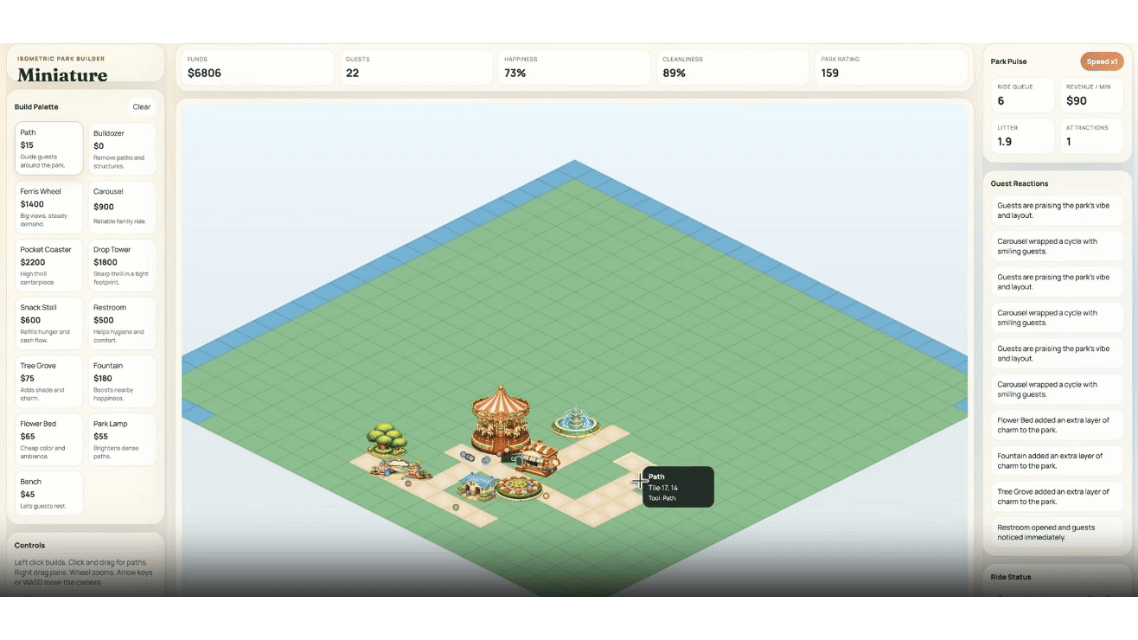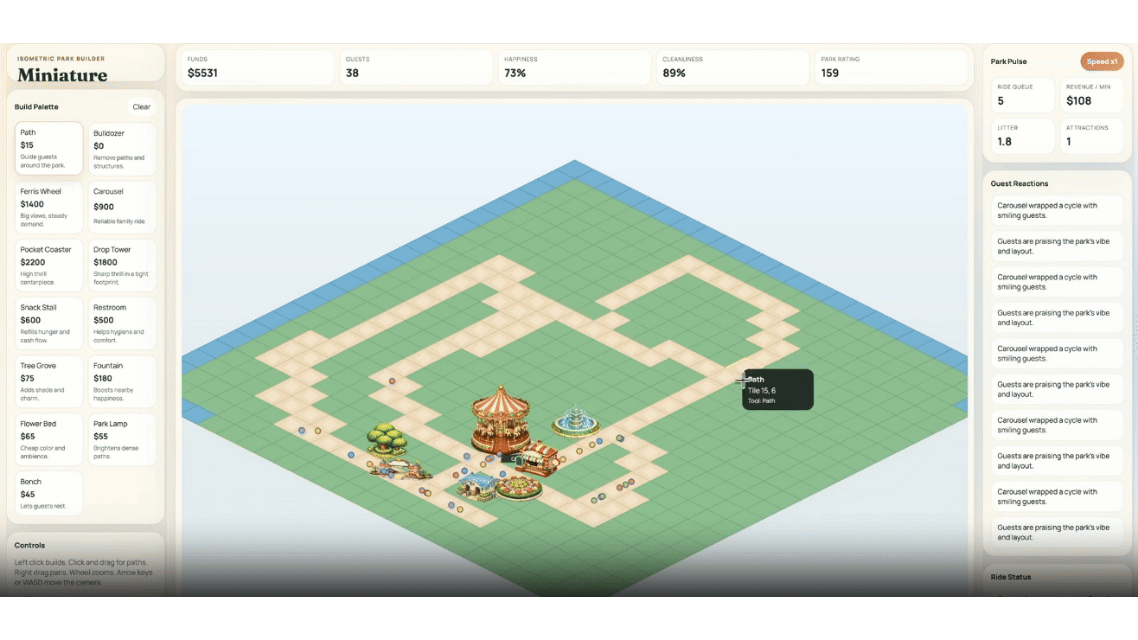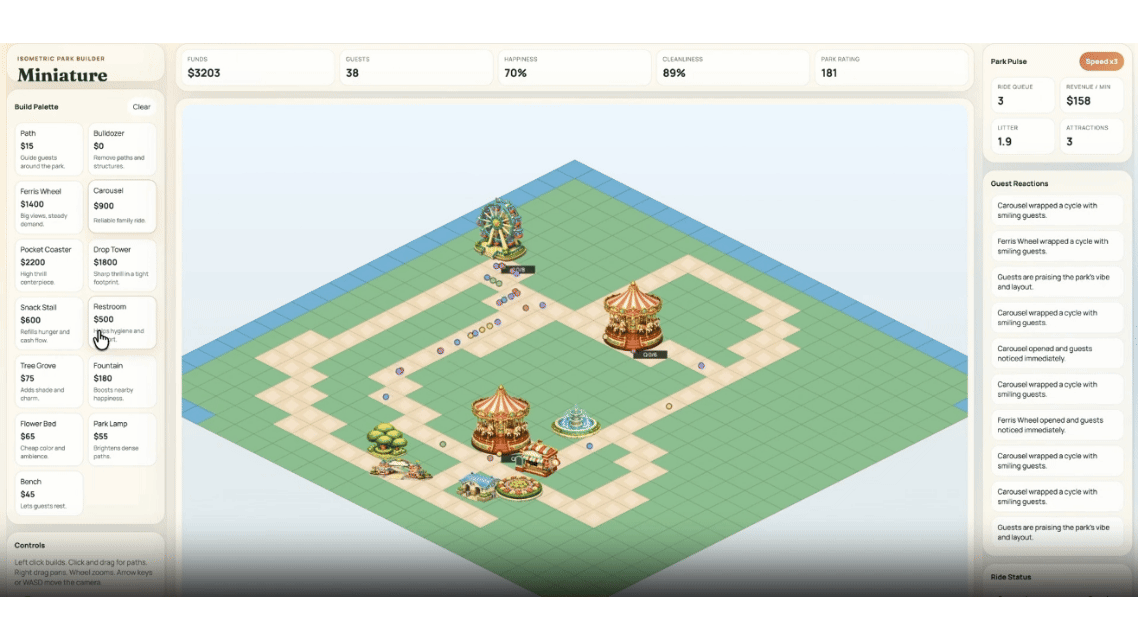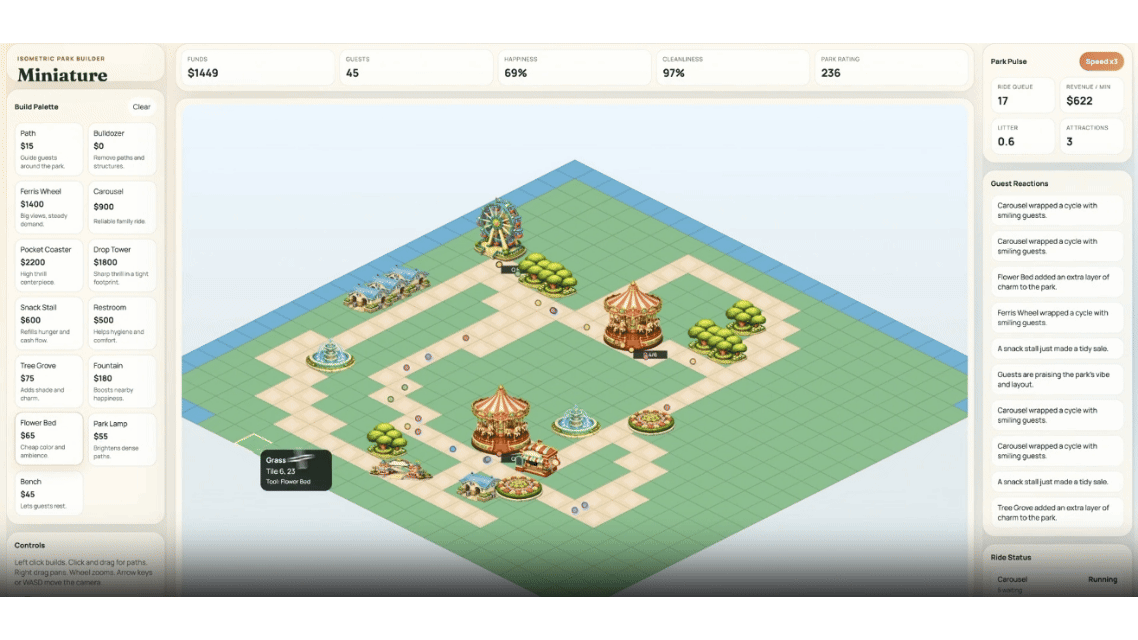
Theme Park Simulation:The system writes code automatically. It generated a complete game including roads and fund management. At the same time, it wrote its own test scripts. The system simulated players building facilities to check if the game crashed.
3D Scene Generation:The system generated a 3D flight program of the Golden Gate Bridge. It handled realistic lighting and traffic.

Information Search and Accuracy Control:GPT-5.4 improves the ability to process internet information. In the BrowseComp web search test, the GPT-5.4 Pro version scored 89.3%. It exceeded Claude Opus 4.6's 84.0%.
Test data shows that GPT-5.4 reduced its probability of declaring errors alone by 33% compared to the previous generation. The probability of it including any factual errors in replies dropped by 18%. The system works more reliably.
Specific Feedback from Five Companies
Companies recorded how GPT-5.4 performed when processing real orders and professional documents.
Finance and Professional Services
Mercor evaluated the model on the APEX-Agents benchmark. CEO Brendan Foody stated that GPT-5.4 ranks first. The system builds long slide decks and complex financial models quickly. It runs faster and costs less than older models. Also, OpenAI released a new ChatGPT for Excel add-in today. Users can process these financial data directly inside their spreadsheets.
Legal Document Analysis
Harvey used the model to process long legal contracts. In the BigLaw Bench test, GPT-5.4 scored 91%. It analyzes complex transaction structures accurately and provides the high-level details that lawyers need.
Large-Scale Web Operations
Mainstay tested the model's computer control abilities. The system visited about 30,000 property tax websites automatically. It achieved a 95% success rate on the first try. Within three tries, the success rate reached 100%. It finishes tasks 3 times faster than older models and uses 70% fewer Tokens.
Code Development and Multi-Step Operations
Cursor engineers reported the system writes code more naturally and decisively. It splits work into parts automatically and runs them at the same time to save time. Zapier's CEO also confirmed that GPT-5.4 finished complex multi-step workflows that previous models gave up on.
API Developer Costs: Specific Prices for Standard and Pro Versions
OpenAI announced the specific use prices for the API:
Service Version | Input Price / 1M Tokens | Output Price / 1M Tokens |
GPT-5.4 (Standard) | $2.50 | $15.00 |
GPT-5.4 (Pro) | $30.00 | $180.00 |
